


Top 7 Javascript Web Scraping Libraries in 2023
Explore the top JavaScript libraries for web scraping in this post, providing you with tools and code samples to enhance your data-gathering effort.


Fetching and analyzing data from websites can be made simple and efficient with the right web scraping tools. For developers who use JavaScript in their daily work, there is a wide array of libraries available to choose from.
Web scraping in JavaScript has become increasingly popular due to the language’s flexibility and widespread use. This article aims to highlight some of the best JavaScript libraries specifically designed for web scraping purposes.
Here are the top 7 Javascript web scraping libraries:
- Cheerio
- Puppeteer
- Playwright
- Selenium
- Crawlee
- Nightmare
- jQuery
If you want to learn how to scrape a website in Javascript, you can read this post.
These libraries offer a variety of functionalities to suit different scraping needs, making it easier for developers to extract information, interact with web pages, and automate data collection processes.
1. Cheerio
Cheerio allows developers to manipulate and traverse HTML documents with a familiar jQuery-like syntax, enabling data extraction and manipulation of HTML content on the server side (NodeJS).
Cheerio landing page screenshot
Three key features of Cheerio:
- Familiar Syntax: Cheerio uses a part of core jQuery, which many developers already know and love. It takes away the tricky parts that come with dealing with browsers, leaving you with a clean and easy-to-use set of tools.
- Super Fast: Cheerio is quick and gets the job done efficiently. Whether you’re changing, reading, or writing your data, it works smoothly and fast, saving you time.
- Very Flexible: Whether your documents are HTML or XML, Cheerio can handle them all. It works great in both web browsers and on servers, making it a flexible choice for different projects.
When to use Cheerio?
Cheerio is especially useful when dealing with web scraping on static content and server-side manipulation of HTML or XML documents.
Cheerio code example
Here is a simple example of how we can scrape a website with Cheerio. We're using Axios to help us fetch the raw HTML.
const axios = require('axios');
const cheerio = require('cheerio');
async function scrapeSite() {
const url = "https://quotes.toscrape.com/"
const data = await axios.get(url);
const $ = cheerio.load(data.data);
// get all data inside .quote class
const results = [];
$('.quote').each((i, elem) => {
const text = $(elem).find('.text').text();
const author = $(elem).find('.author').text();
const tags = [];
$(elem).find('.tag').each((i, elem) => {
tags.push($(elem).text());
});
results.push({ text, author, tags });
});
return results;
}
scrapeSite().then(result => {
console.log(result)
}).catch(err => console.log(err));
This is the original HTML structure:
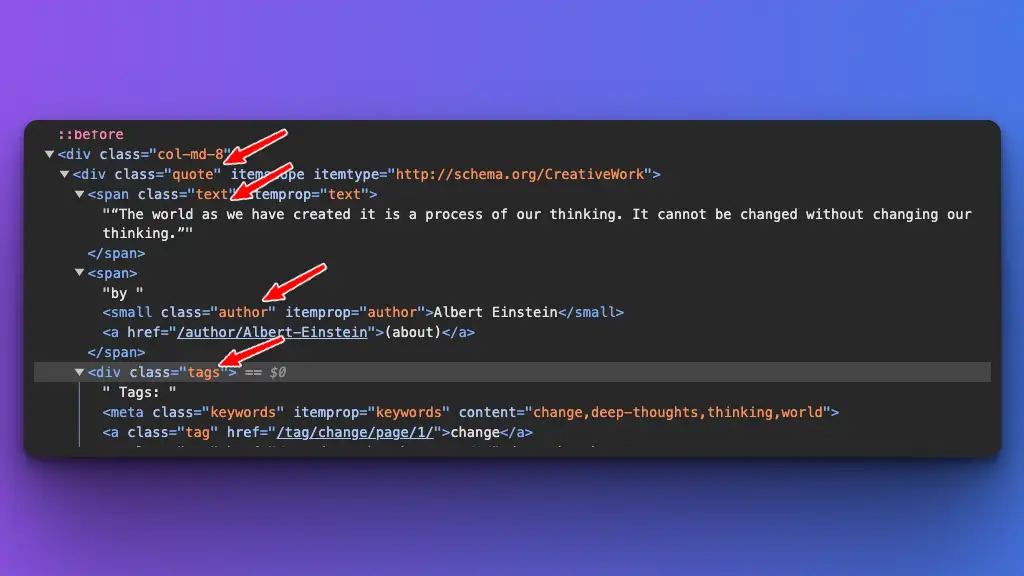
raw HTML original structure from toscrape.
GitHub: https://github.com/cheeriojs/cheerio
Documentation: https://cheerio.js.org/
2. Puppeteer
Imagine being able to control your browser through programming! Puppeteer is designed to assist you in doing just that.
Puppeteer landing page screenshot
Puppeteer is a Node library developed by the Google Chrome team that provides a high-level API to control headless Chrome browsers over the DevTools Protocol. Pretty much anything you can do by hand in a browser, you can also do with Puppeteer.
Some things you could do with Puppeteer:
- "Create images and PDFs of different web pages."
- "Go through a Single-Page Application (SPA) and make content that is pre-rendered, also known as Server-Side Rendering (SSR)."
- "Fill out forms, test user interfaces, and simulate typing on a keyboard automatically."
- "Record a timeline of your site’s activity to figure out and solve performance problems."
- "Testing Chrome Extensions"
When to use Puppeteer?
Use Puppeteer when you need to scrape websites that rely on JavaScript to load their content or even Single Page Applications (SPAs). Puppeteer can execute JavaScript, making it capable of interacting with dynamic web pages.
Also, if your scraping task requires interacting with the page (clicking buttons, filling out forms, navigating through a multi-step process), Puppeteer is well-suited for these types of interactions.
Puppeter code example
Here is a short puppeteer demonstration on how to scroll a page, wait for a specific element, detect CSS class, and finally collect the results.
const puppeteer = require('puppeteer');
(async () => {
// Launch the browser and open a new blank page
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Navigate the page to a URL
await page.goto('https://quotes.toscrape.com/scroll');
// Set screen size
await page.setViewport({width: 1080, height: 1024});
// wait for '.quotes' only == first data init finsihed
await page.waitForSelector('.quotes');
// scroll to the bottom of the page
await page.evaluate(() => {
window.scrollBy(0, window.innerHeight);
});
// wait for '#loading' has display: none
await page.waitForSelector('#loading', {hidden: true});
// wait for '.quotes'
// and collect new quotes (.text, .author, .tags)
const quotes = await page.evaluate(() => {
const quotes = [];
document.querySelectorAll('.quote').forEach((quote) => {
quotes.push({
text: quote.querySelector('.text').textContent,
author: quote.querySelector('.author').textContent,
tags: quote.querySelector('.tags').textContent
});
}
);
return quotes;
})
// Print out the quotes
console.log(quotes);
await browser.close();
})();
GitHub: https://github.com/puppeteer/puppeteer
Documentation: https://pptr.dev/
3. Playwright
Playwright is a Node.js library that provides a high-level API to automate and control web browsers, making it a powerful tool for web scraping, browser testing, and web automation.

Playwright landing page screenshot
Developed by Microsoft, Playwright supports multiple browsers, including Chromium, Firefox, and WebKit, offering cross-browser capabilities.
These are some key features from Playwright, but not limited to:
- Browser Automation: Playwright automates browser interactions, enabling you to load web pages, click buttons, fill out forms, and perform other actions as a user would.
- Handling Dynamic Content: Since Playwright controls a real browser, just like Puppeteer, it can handle JavaScript-heavy and dynamically loaded content, ensuring that you can scrape data even from websites that rely heavily on client-side rendering.
- Multiple Browser Support: With support for Chromium, Firefox, and WebKit, Playwright allows you to scrape websites across different browsers, helping ensure consistency and compatibility.
- Screenshots and PDFs: Playwright can capture screenshots of web pages and generate PDFs, which can be useful for saving information or debugging your scraping scripts.
- Concurrency and Performance: Playwright is designed for performance and can handle multiple browser instances and pages concurrently, making it efficient for large-scale scraping tasks.
When to use Playwright?
Just like Puppeteer, you can use Playwright for javascript-heavy or dynamically loaded content. But Playwright supports multiple browsers and other programming languages, not just Javascript.
Playwright code example
This is a basic code example of Playwright. The flow is very similar to Puppeteer since both will launch a browser for use, so we can navigate through the content just like we would on the real website.
const { chromium } = require('playwright');
(async () => {
// Launch the browser and open a new blank page
const browser = await chromium.launch();
const page = await browser.newPage();
// Navigate the page to a URL
await page.goto('https://quotes.toscrape.com/scroll');
// Set screen size
await page.setViewportSize({ width: 1080, height: 1024 });
// wait for '.quotes' only == first data init finished
await page.waitForSelector('.quotes');
// scroll to the bottom of the page
await page.evaluate(() => window.scrollBy(0, window.innerHeight));
// wait for '#loading' has display: none
await page.waitForSelector('#loading', { state: 'hidden' });
// wait for '.quotes'
// and collect new quotes (.text, .author, .tags)
const quotes = await page.evaluate(() => {
const quotes = [];
document.querySelectorAll('.quote').forEach((quote) => {
const text = quote.querySelector('.text')?.textContent || '';
const author = quote.querySelector('.author')?.textContent || '';
const tags = quote.querySelector('.tags')?.textContent || '';
quotes.push({ text, author, tags });
});
return quotes;
});
// Print out the quotes
console.log(quotes);
await browser.close();
})();
GitHub: https://github.com/SeleniumHQ/selenium
Documentation: https://playwright.dev/
4. Selenium
Selenium WebDriver is a widely-used tool primarily designed for automating web browsers, making it useful for web scraping as well as testing web applications. Selenium WebDriver is a part of the Selenium suite of tools, providing a programming interface to write scripts that can perform actions in web browsers, just like a human would.

Selenium landing page screenshot
Things you could do with Selenium:
- Browser Automation: Selenium WebDriver allows you to navigate through websites programmatically, click on links, fill out forms, and interact with different web elements.
- Handling Dynamic Content: Since WebDriver controls an actual browser, it can interact with and scrape data from websites that rely on JavaScript to load content.
- Cross-Browser Compatibility: You can write your scraping scripts once and run them on different browsers, ensuring that your application works consistently across various environments.
- Handling AJAX and Client-Side Rendering: WebDriver can wait for AJAX calls to complete and JavaScript to render content, making it possible to scrape data from complex web applications.
- Extracting Data: Once you’ve navigated to the right part of the web page and waited for the content to load, you can use WebDriver to extract text, attributes, and other data from web elements.
- Screenshot Capturing: WebDriver has built-in capabilities to take screenshots of web pages, which can be useful for debugging or archiving purposes.
GitHub: https://github.com/SeleniumHQ/selenium
Documentation: https://www.selenium.dev/documentation/webdriver/
5. Crawlee
Crawlee is a web scraping library developed by Apify. It provides a high-level API to control browser sessions and automate processes in JavaScript, making it easier for developers to scrape websites, automate browser tasks, and handle various web scraping-related challenges.

Crawlee landing page screenshot
Key features from Crawlee:
- Single interface for HTTP and headless browser crawling
- Persistent queue for URLs to crawl (breadth & depth first)
- Pluggable storage of both tabular data and files
- Automatic scaling with available system resources
- Integrated proxy rotation and session management
GitHub: https://github.com/apify/crawlee
Documentation: https://crawlee.dev/
6. Nightmare
Nightmare is a high-level browser automation library for Node.js. It is designed to simplify the process of setting up, writing, and maintaining browser automation, user interface testing, and web scraping scripts.
Warning: Nightmare library is no longer maintained.
GitHub: https://github.com/segment-boneyard/nightmare
7. jQuery
jQuery is a fast, small, and feature-rich JavaScript library that simplifies things like HTML document traversal and manipulation, event handling, and animation. Using jQuery for web scraping involves utilizing its concise and powerful syntax to traverse and manipulate the Document Object Model (DOM) of a webpage.

jQuery landing page screenshot
jQuery is a powerful tool for web scraping on the client side within the browser.
When to use jQuery for web scraping?
If you quickly need to extract data from a webpage you are visiting, you can use the browser’s console to run jQuery commands and scrape data. It's also perfect for prototyping. You can quickly prototype your scraping scripts in the browser before implementing a more robust solution on the server side.
jQuery web scraping code example
We'll use the same case from the Puppeteer and Playwright examples, where we want to collect quotes from this site https://quotes.toscrape.com/scroll.
Since jQuery is running in the client's browser, you need to visit the URL with your actual browser.
Then, right-click and open developer tools. Now, you can copy and paste this code:
$(document).ready(function () {
// Ensure the '.quotes' element is present
if ($('.quotes').length > 0) {
// Scroll to the bottom of the page
$(window).scrollTop($(document).height());
// Check if '#loading' is hidden
var checkLoading = setInterval(function () {
if ($('#loading').css('display') === 'none') {
// Clear the interval once '#loading' is hidden
clearInterval(checkLoading);
// Collect quotes and log them
var quotes = $('.quote').map(function () {
return {
text: $(this).find('.text').text(),
author: $(this).find('.author').text(),
tags: $(this).find('.tags').text()
};
}).get();
console.log(quotes);
}
}, 100); // Check every 100 milliseconds
} else {
console.error("'.quotes' element not found");
}
});
GitHub: https://github.com/jquery/jquery
Documentation: https://jquery.com/
8. Bonus
Table of Web Scraping Libraries for Javascript
We are omitting HTTP Client libraries from our web scraping libraries, as these tools serve a broader range of purposes and are not exclusively used for web scraping.
Below, you will find a comprehensive table of tools specifically related to web scraping in JavaScript, including HTTP Client tools.
| Name | Category |
| Cheerio | HTML Parsing |
| jQuery | HTML Parsing |
| Selenium | Browser Automation |
| Playwright | Browser Automation |
| Puppeteer | Browser Automation |
| Nightmare | Browser Automation |
| Crawlee | Browser Automation |
| Node-Crawler | HTML Parsing |
| htmlparser2 | HTML Parsing |
| parse5 | HTML Parsing |
| Request | HTTP Client |
| Axios | HTTP Client |
| SuperAgent | HTTP Client |
| Needle | HTTP Client |
| node-fetch | HTTP Client |
Please note that while jQuery can be used for web scraping in browser environments, it is primarily a DOM manipulation library. Also, HTTP Client libraries are included in this list for completeness, as they can be used in conjunction with other tools for web scraping tasks.
If you're looking for an easy way to scrape search engine results, including Google, Yahoo, Bing, Baidu, and more, you can try SerpApi for free.